

Data Integration and Automated Updates for Web Applications
The COVID-19 pandemic brought real-time data analytics and visualization into the forefront of news and public discussion. The pandemic so far has led to the creation of an unprecedented amount of publicly available epidemiological data from municipal to the global scales. These data serve pandemic response, and will be valuable resource for education and emergency preparedness for decades to come. In this blog post we review the common features of the COVID-19 related data interfaces, so called APIs, and showcase data integration and automation using the data behind the COVID-19 application developed by Analythium.
The first COVID-19 dashboard was made by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University. Since then, many regional, national, and international data sets have been catalogued and made available for the public (see e.g. this collection of APIs). The data behind the CSSE dashboard, however, still remains one of the most used data sources. It is available from a GitHub repository and is refreshed at least once a day. The community is very active around this data set, providing updates and corrections.
Wide Format Data
The data format of the CSSE data set is comma separated (CSV) text file. CSV is a flat file format. Its structure also referred to as a wide format, where rows are political jurisdictions (countries, states, provinces, territories) and columns are calendar days:
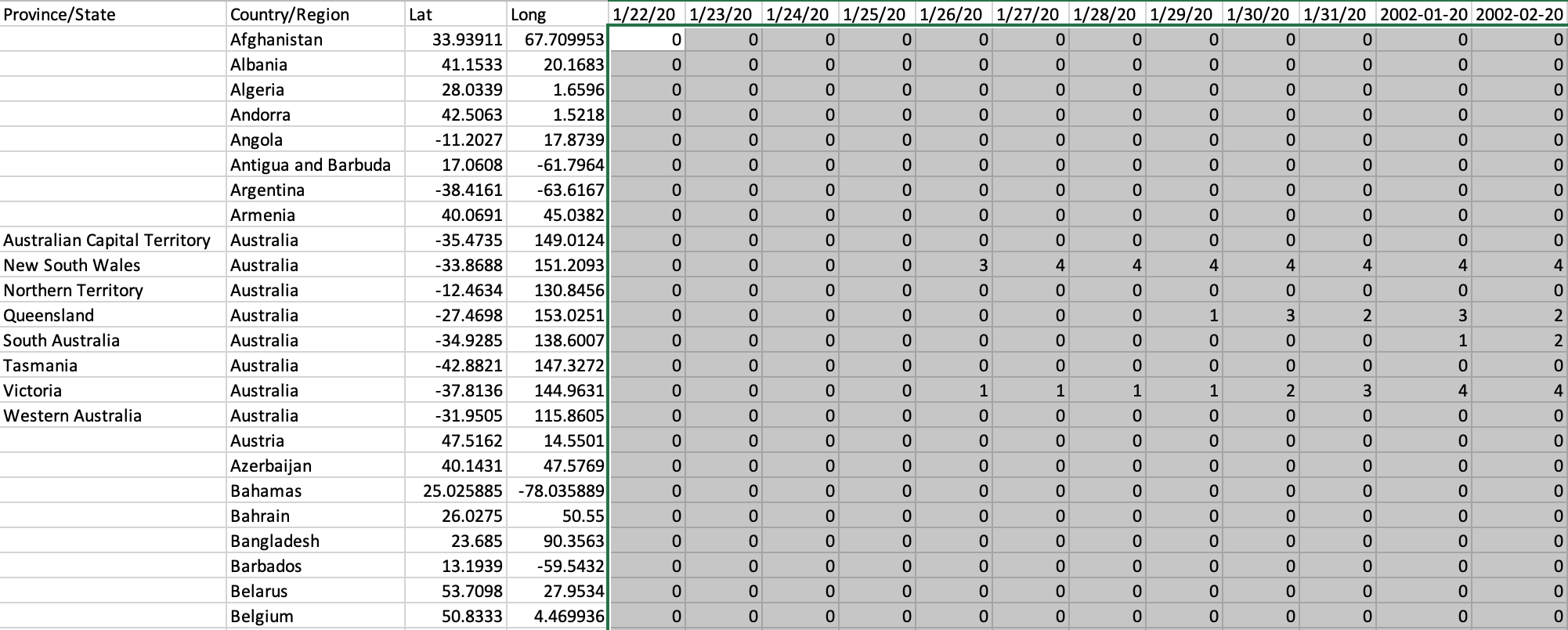
This is the type of formatting that facilitates the comparison across regions, because we can directly compare values from different rows. The format is also helpful for knowing the latest case counts by just looking at the last column that has numbers from the last update. If we want to know the number of recovered cases or the number of deaths, we need an identically formatted table where the cell values refer to recovered cases or deaths instead of the confirmed cases. Storing such data in separate files might require more checks to ensure compatibility (i.e. identical row and column ordering) before comparing the tables to each other.
Long Format Data
An alternative way of organizing COVID-19 case counts is a long format data where we have column(s) referring to the political jurisdictions, another column contains the dates. We can then add the confirmed cases, the recovered cases, and deaths as additional columns. An example for such data structure is the downloadable information from the Public Health Infobase by the Government of Canada:
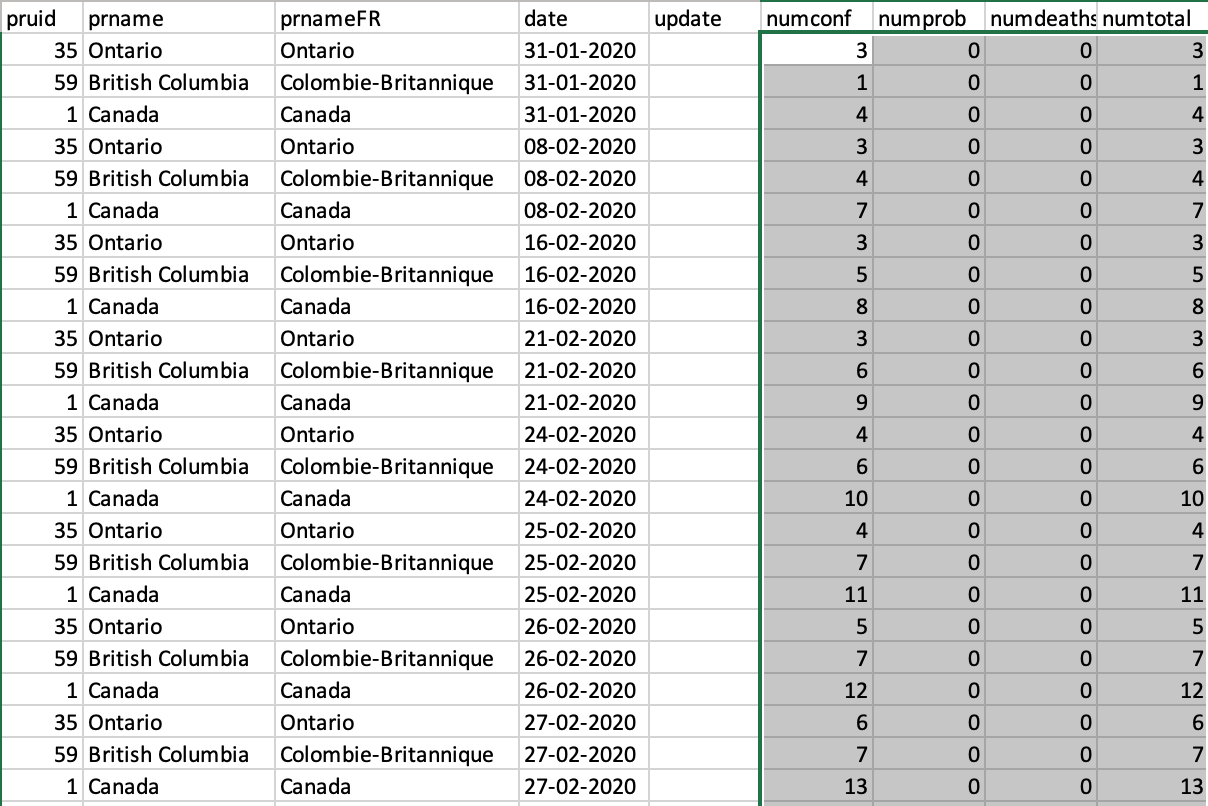
This is also in CSV format that has the advantage of being accessible from any scripting and spreadsheet software. This table can be easily filtered by region or date, and the different case numbers are going to remain consistent. However, direct comparison across regions over time needs more data processing. As a result, the raw long format table often rendered into a set of derivative wide format tables.
Unstructured Data
The third common type of data is unstructured. Here unstructured means that the data is a heterogeneous set of information without an overarching schema. Such data is typically the result of web scraping, i.e. when websites are read and parsed to extract information directly from the hypertext (HTML) source file. An example for such data sets is the interactive aggregate data on COVID-19 cases in Alberta regularly produced by Alberta Health:
Data Integration
Data integration takes different input data streams and outputs data in a standardized format. Such standardized data then can be used in different applications without the need to read in huge amounts of data or to do data processing. The data is formatted and presented in a way that makes it suitable for consumption by web applications through application programming interfaces (APIs). A common data interchange format is the text based and language-independent JavaScript Object Notation (JSON).
At Analythium, we took the global, Canadian, and Alberta data and reformatted these according to a common data schema to provide an JSON API for our COVID-19 application (read more about that app here and here). This API demonstrates how scripting computer languages can be used to standardize wide, long format, and unstructured data. The description of the API can be found in our GitHub repository.
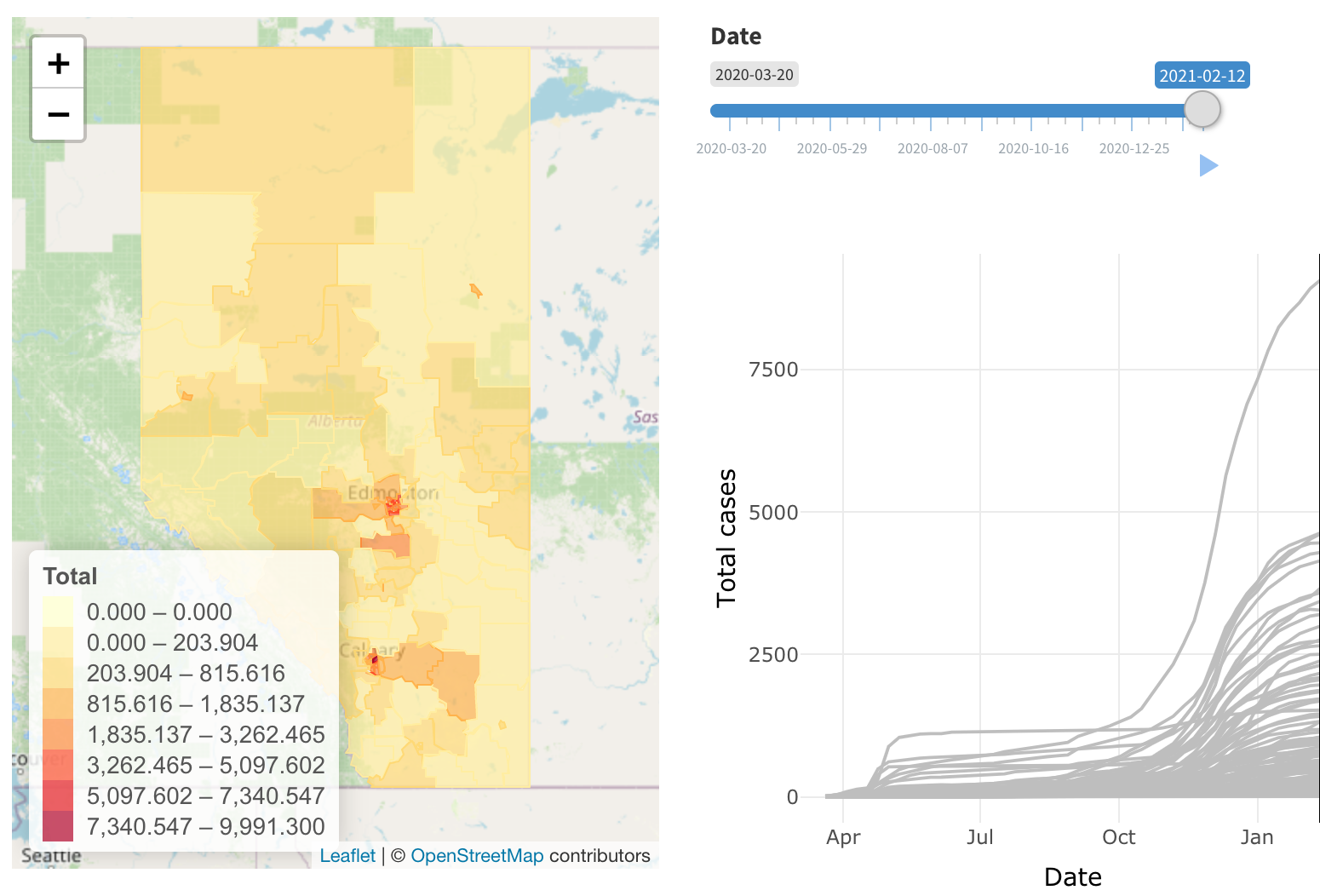
The benefit of this api is that the queries can refer to various levels of data aggregation, e.g. global, country level, state/province level, or even county level data can be extracted in a standardized format without the need to load any other data that is not of interest. This helps the web applications relying on the data to respond to user queries much faster.
Automated Data Processing
We started to build Analythium's COVID-19 data API on March 17th, 2020. Since then, we updated the data set every single day. To do so, we set up automation to repeat the tasks without human intervention. Once in a while, we detected changes in the incoming data structures and we had to modify our scripts accordingly. But the automated scripts have run in a predictable manner ever since, resulting in daily updated data to feed our web application. The following flow chart summarizes the steps in the automated data processing pipeline from the three kinds of incoming data to the final data API:
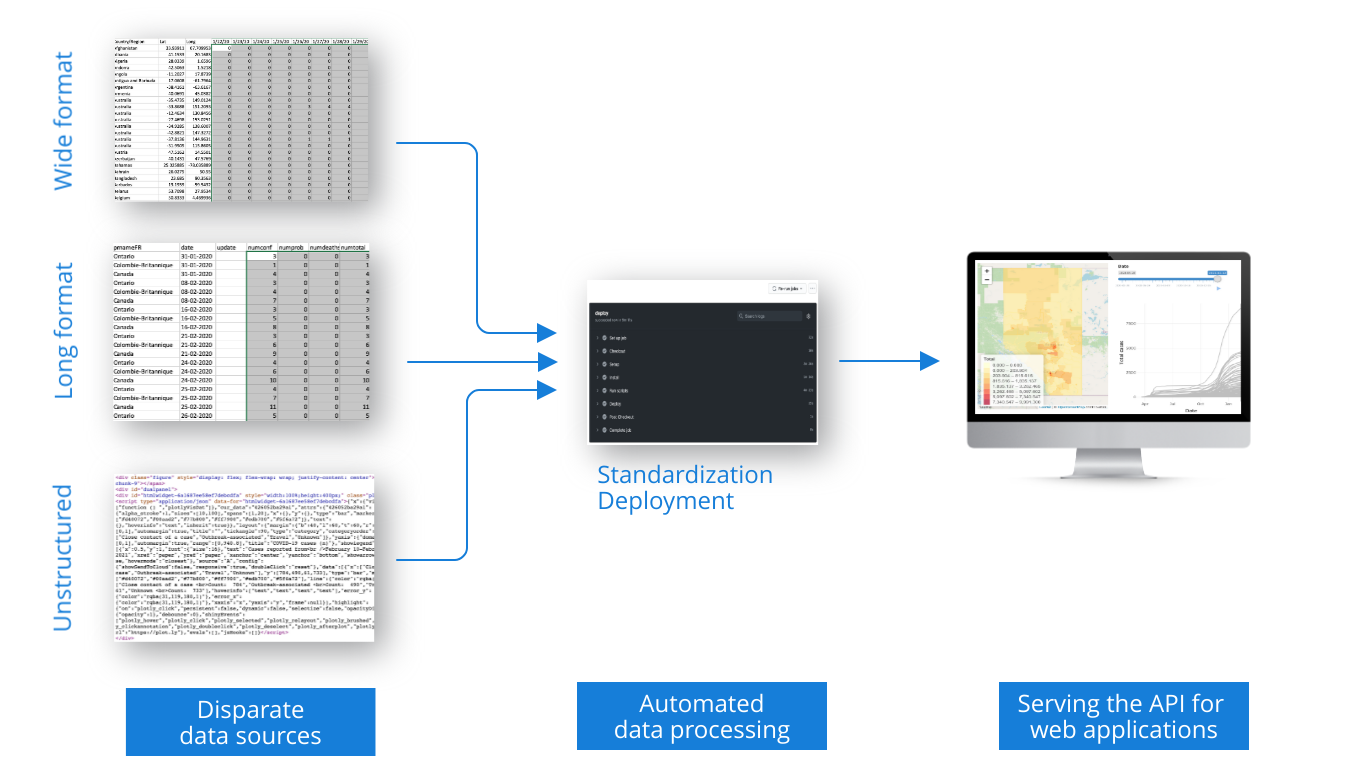
Next Steps
Carefully scripted data automations and well designed interfaces can serve various web applications. This is true for COVID-19 as well as for any other app that relies on frequently updated or streaming data as inputs. Continuous integration and delivery plays an important role in automation. Analythium's value proposition is to offer affordable and customized data analytics solutions. We continuously improve our systems and processes to incorporate the latest technological innovation into our toolbox.
If this post picked your interest, sign up for our newsletter below to get notifications about future updates. If you have disparate data sources that you want to standardize and automate, we can help! Schedule a free consultation or visit our website to learn more our data science, and machine learning solutions.



